Interpreting Learning Rate Values
When you first started to experiment with fine-tuning using SFT Trainer, you may well have noticed something termed a learning rate with an exponent value like 5e-6, it can feel like stumbling across hieroglyphics or an unfamiliar math notation. However, as cryptic as it seems, the notation itself is actually easier to understand than how it may first appear. The scientific shorthand for 5e-6 — means 5 × 10⁻⁶, or 0.000005. That's five millionths. It's a vanishingly small number, and understanding why anyone would choose such a tiny value requires grasping what learning rates actually do.
A neural network learns by adjusting its parameters in response to errors. The learning rate determines the size of each adjustment.
I used to spend a lot of time in the British mountains in winter, sometimes acsending steep icy slopes with crampons. Each step had to be deliberate and measured, so I would sometimes waddle along like a pigeon - a misstep could mean a slip and a dangerous fall. This was made even riskier by the often-poor visibility. In a similar way, the learning rate controls how boldly or cautiously the model steps through its parameter space. A high learning rate is like taking big strides—potentially covering ground quickly but risking overshooting the target (overfit). A low learning rate is akin to careful, small steps—safer, but slower.
The reason learning rates tend to come as such small decimals boils down to gradient magnitudes. Gradients if you're not already familiar, are the mathematical signals telling the network which direction to adjust—can be quite large, especially in deep networks. A learning rate of 1.0 combined with a gradient of 50 would shift a parameter by 50 units in a single step. That kind of violent update would likely destroy any useful representations the network had started to form. By using learning rates like 0.001 (written 1e-3) or 0.0001 (1e-4), we tame these updates into something the network can absorb gracefully.
Different tasks and architectures call for different scales. Training a small image classifier from scratch might work well with a learning rate around 1e-3. Fine-tuning a large language model, where you're making delicate adjustments to billions of pre-trained parameters, often demands something in the 1e-5 to 1e-6 range. The intuition here is preservation: you want to nudge the model toward your specific task without obliterating the general knowledge it already contains. A learning rate of 5e-6 says, in effect, "change very little with each step, because most of what you already know is valuable."

The relationship between batch size and learning rate adds another dimension. Larger batches produce more stable gradient estimates, which can tolerate—and sometimes require—higher learning rates. A common heuristic is linear scaling: if you double your batch size, you might double your learning rate. This keeps the effective scale of updates roughly constant. You'll often see papers report learning rates alongside batch sizes for exactly this reason; the numbers are meaningfully connected.
Learning rate schedules complicate matters further, but in an illuminating way. Many training runs don't use a single fixed learning rate. They might start with a warmup phase, gradually increasing from near-zero to some peak value, then decay over time according to a cosine curve or step function. The peak learning rate—say, 2e-4—represents the maximum stride the optimizer will take. The schedule acknowledges that different phases of training benefit from different step sizes: cautious exploration early on, confident strides in the middle, and careful refinement toward the end.
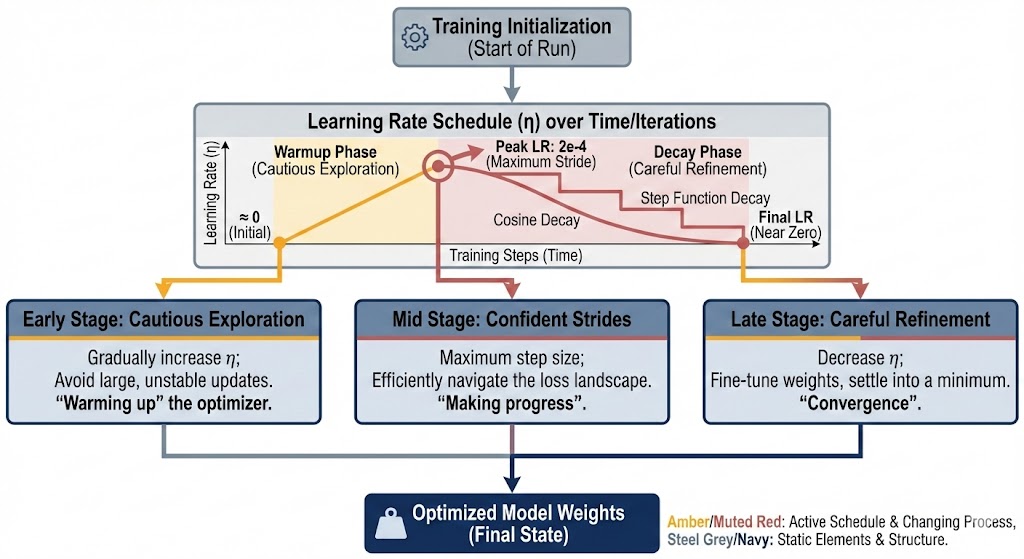
When you see a learning rate like 3e-5 in a research paper, you can now read it with context. That's 0.00003, a value suggesting either a large pre-trained model being fine-tuned, or perhaps a particularly sensitive optimization landscape. The authors chose it through some combination of theory, heuristics, and empirical tuning—probably a grid search or sweep that tested values spanning several orders of magnitude. Learning rate selection remains more art than science, guided by accumulated wisdom about what tends to work for different model families and tasks.
Notation rundown
So the scientific notation itself is just convenience. I now fine the most useful thing is ease of reading. Writing 0.000005 repeatedly is error-prone to type and hard to compare at a glance. The e notation—borrowed from calculators and programming languages—makes it trivial to see that 5e-6 is ten times smaller than 5e-5. When scanning a configuration file or hyperparameter table, this clarity matters. You can immediately spot that one experiment used a learning rate a hundred times larger than another, which might explain why it diverged spectacularly during training.
Ultimately, a learning rate is a statement of trust. High values say: "I believe large updates will point in roughly the right direction." Low values say: "I'm uncertain, so I'll step carefully."
Values like 5e-6 represent extreme caution—appropriate when working with massive models where a single misstep can waste days of compute, or when the goal is gentle adaptation rather than wholesale learning. Reading these numbers becomes intuitive with practice, each one telling a small story about the training regime it belongs to.
Want to learn more about Always Further?
Come chat with a founder! Get in touch with us today to explore how we can help you secure your AI agents and infrastructure.