Why Your Classification Task Doesn't Need a $20M Model
Large Language Models are often overkill.
LLMs like GPT-5 and Opus 4.5 are genuinely impressive. Their few-shot learning capabilities allow teams to prototype AI features in minutes - write a prompt, and suddenly something works. This is the right approach, I encourage anyone prototyping , to use a large model - but always have the view to optimise when you know you have things settled. As for narrow, well-defined production tasks, this approach burns money and adds latency for no good reason.
Having spoken with a few startups building AI-powered products, I've seen this mistake repeatedly: teams default to LLMs for everything, then wonder why their infrastructure costs are spiralling and their response times are inconsistent, all resulting in a frustrating UX for their users. Quite often it's all down to using the wrong tool for the job.
Understanding the difference between generative models and other methods, namely classifiers, is the maturity milestone that separates AI experimenters from AI operators.
Two Different Tools for Two Different Jobs
Before we go further, let's clarify something that is rarely understood well: not all neural networks do the same thing, and the model that dominates headlines isn't necessarily the model you need.
We are going to focus on two broad categories of models: Large Language Models (LLMs) like GPT-5, Claude, and LLaMA, and classification models like BERT, RoBERTa, and DistilBERT.
Large Language Models are generators. When you ask an LLM a question, it's predicting the next word (token), then the next, then the next - constructing a response one token at a time. This autoregressive process is what allows LLMs to write essays, draft emails, summarize documents, and hold conversations. They're extraordinarily flexible because their output space is essentially unlimited: any sequence of words is fair game.
Classifier models are decision-makers. They take an input - a sentence, a paragraph, an email - and assign it to one of a predetermined set of categories. That's it. No generation, no creativity, no conversation. Just a fast, confident answer: this input belongs to Category A, Category B, or Category C. They can also be used for regression tasks, predicting a continuous value rather than discrete labels, but the core idea remains the same: mapping inputs to outputs in a fixed space. In Always Further, we use classifiers for tasks like sentiment analysis, intent detection, topic categorization, and more.
This distinction matters enormously, because most of the AI running in production today isn't generating anything. It's classifying.
You will already be engaged with classification models daily, probably without realising it.
The AI that you interact with daily on many huge services? Most of it isn't generative - it's classificatory.
When you type a query into Google, a classifier determines your intent (BERT in fact). Are you looking to buy something, learn something, or navigate somewhere? That classification shapes everything about the results you see. When you ask Siri or Alexa a question, the first thing that happens isn't generation - it's classification. The system categorizes your request (play music, send a message, take a note, set an alarm clock, ask a general question) before routing it to the appropriate handler.
Your email inbox is powered by classifiers. Gmail's spam filter, priority inbox, and category tabs (Primary, Social, Promotions) all rely on classification models making rapid decisions about every message that arrives. The same is true for document management systems that automatically sort files, customer service platforms that route tickets to the right department, and content moderation systems that flag policy violations at scale.
These systems handle millions of requests per second. They need to be fast, cheap, and reliable. They cannot afford the latency of generating a response token by token. They cannot afford to "hallucinate" a category that doesn't exist. They need to make a decision and move on.
This is the domain of encoder-only models like BERT, RoBERTa, and DistilBERT - and it's a domain where LLMs are dramatically overqualified and will highly likely underperform. Not because LLMs are bad, but because they're the wrong tool for the job. It's like using a top spec gaming PC to play Solitaire.
Architectural Differences
The architectural difference between these model types can have massive downstream consequences.
As LLMs are autoregressive. Every token you generate costs compute or credits. And every token adds latency, as it passes through expensive transformer layers. It's like paying a master chef to make you nice cup of tea in the morning.
As BERT-style classifiers are encoder-only: they process your entire input sequence in parallel and output a classification in a single forward pass. No generation loop. No variable latency. Just fast, deterministic inference.
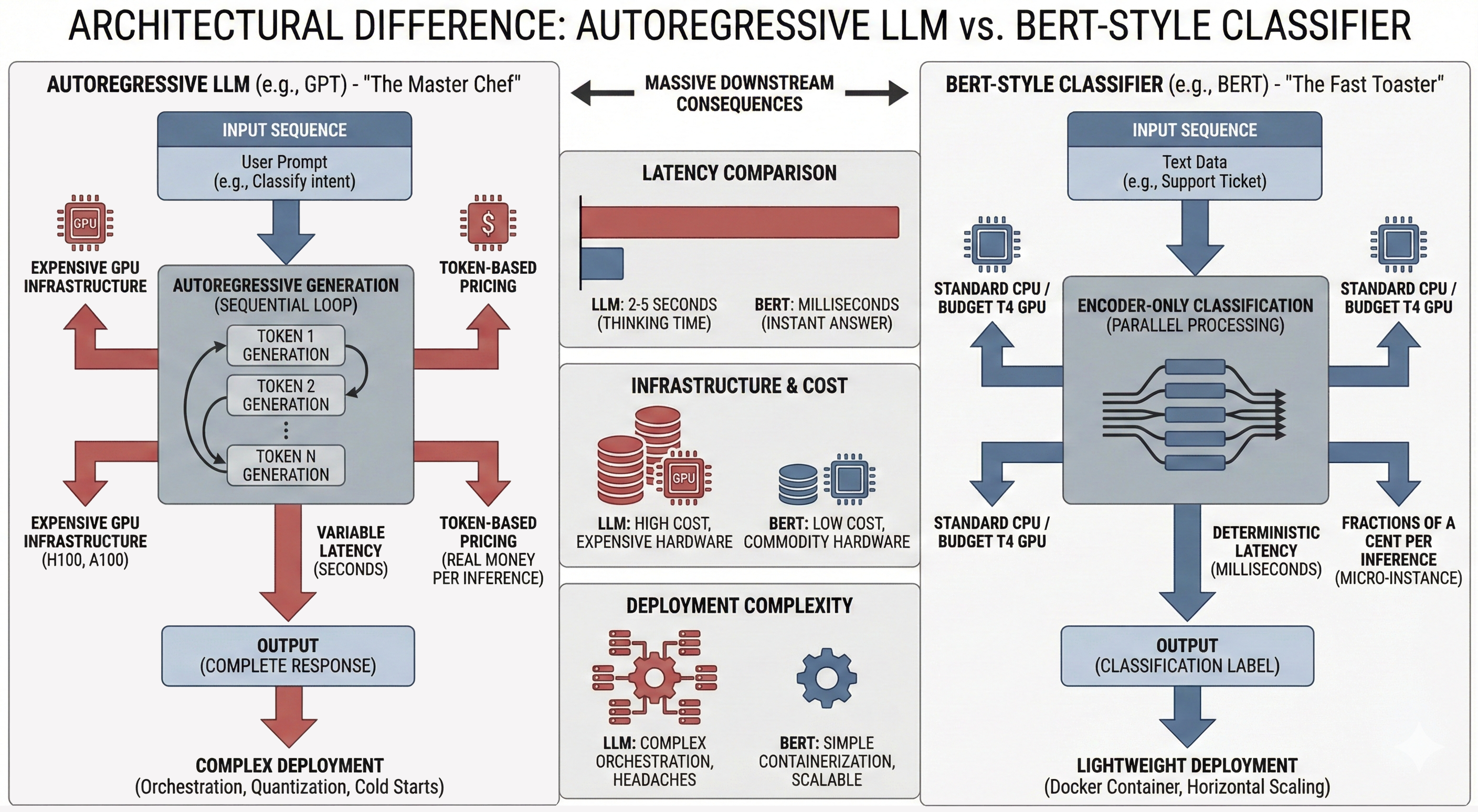
In practical terms, this means an LLM might take two to five seconds to classify a piece of text (even longer if its a reasoning model), whereas a BERT classifier returns an answer in milliseconds. The LLM requires expensive GPU infrastructure - H100s or A100s, while a classifier can run comfortably on a standard CPU or a budget T4 GPU. The LLM costs real money per inference through token-based pricing; the classifier costs fractions of a cent on a simple micro-instance.
Deployment complexity follows the same pattern. Running an LLM in production requires orchestration, quantization, caching strategies, and careful attention to cold start times. A classifier fits in a lightweight Docker container and scales horizontally with minimal fuss.
If you're running classification at scale - intent detection, sentiment analysis, content moderation, ticket routing, document sorting - these differences compound into real money and real engineering headaches.
Accuracy
Smaller models often perform better on narrow tasks and this is especially true for classification.
The first reason is that classifiers can't hallucinate. A classifier has a fixed output space. It returns Label A, Label B, or Label C. It cannot ramble. It cannot hedge with "As an AI language model, I think this might be..." It cannot confidently invent a fourth category that doesn't exist. For production systems that need deterministic, predictable behavior, this constraint is a feature, not a bug.
The second reason is domain specificity. A BERT model fine-tuned on 500 examples of your specific data - your edge cases, your terminology, your label definitions - will almost always outperform a general-purpose LLM on that specific task. The LLM knows a little about everything; your fine-tuned classifier knows a lot about the one thing that matters to your business.
Prototyping
So why do people still default to LLMs for classification tasks? The answer is prototyping speed.
With an LLM, you craft a prompt, write some scaffold code and ship something that works "well enough." The barrier to entry is very minimal. With traditional fine-tuning, you need to gather data, label it, set up training infrastructure, debug CUDA errors, tune hyperparameters, and hope everything converges. That friction is real, and it's why the LLM-for-everything-as-a-service approach became the go to at so many organizations.
But become reliant on LLMs for everything, and that prototyping speed advantage quickly evaporates as you scale and then becomes an expensive liability and an engineering headache. As your volume grows, latency increases, edge cases multiply, users churn from a slow UX and costs balloon. The initial convenience of the LLM becomes a long-term liability.
The Hybrid Approach: Best of Both Worlds
Most teams will use what is often termed a Distillation Pipeline, and it leverages the strengths of both approaches.
First, you use an LLM as a synthetic annotator. Have GPT-4 or Claude label a thousand raw examples based on your criteria. LLMs are excellent at this - they understand nuance, they can follow complex labeling guidelines, and they work fast enough to generate training data in hours rather than weeks.
Quite often, a tool like DeepFabric can be excellent for this, especially with its topic driven data generation capabilities.
Second, you train a BERT classifier on that LLM-labeled data. Fine-tuning BERT on a few thousand examples is straightforward and quick. The model learns to replicate the LLM's labeling behavior but does so in a way that's optimized for speed and efficiency.
Third, you deploy the classifier. Fast inference, low cost, deterministic behavior, simple infrastructure. All of the common inference stacks such as vLLM, TorchServe etc can handle this with relative ease.
This approach gives you the intelligence of the LLM at labeling time and the speed and economics of a classifier at inference time. The LLM becomes your expert annotator, not your production bottleneck.
Where LLMs Still Make Sense
This isn't an anti-LLM argument. LLMs are the right tool when a task requires genuine generation - writing, summarization, code synthesis, open-ended conversation. They excel when the output space is unbounded or constantly changing, during exploration phases before requirements are clear, or when conversational context across multiple turns is essential.
But for classification? For routing? For yes/no decisions at scale? For all the invisible AI infrastructure that sorts your emails, interprets your voice commands, and categorizes your documents? You're leaving money and milliseconds on the table by using a generative model.
The Maturity Milestone
A clear pattern emerges at organizations that have figured out AI deployment and understand the past few decades of Machine Learning has not been a desert devoid of innovation until the arrival of LLMs.
In the first phase, everything goes to the LLM. It works. Costs are manageable because volume is low. In the second phase, scale hits. Latency matters. Costs balloon. Edge cases multiply. Reliability becomes a concern. In the third phase, teams start asking, "Wait, do we actually need an LLM for this?" The answer is usually no. In the fourth phase, narrow tasks get distilled into purpose-built classifiers while LLMs get reserved for tasks that genuinely require generation.
Phase four is where the mature organizations live. It's where unit economics makes sense, systems are reliable, and AI infrastructure is sustainable at scale.
When to switch
If your team is still routing classification tasks through an LLM and wondering why infrastructure costs keep climbing, it might be time to reconsider the architecture.
The investment in building a streamlined fine-tuning pipeline pays off quickly. Once the friction of training a classifier drops to near zero, the calculus changes entirely. Suddenly the "fast prototype" advantage of LLMs disappears, and what remains is a clear choice: pay more for slower, less predictable inference, or deploy purpose-built models that do exactly what you need.
How Always Further Trains their BERT models in Seconds
At AlwaysFurther, we've built an internal pipeline that collapses the fine-tuning workflow into something quite simple and quick. Forty-five seconds approx. That's the time from a labeled dataset to a production-ready classifier.
No GPU cluster provisioning. No hyperparameter sweeps. No MLOps complexity. The pipeline accepts datasets in whatever format we have and handles tokenization, train/validation splits, optimal learning rate scheduling, early stopping, and model selection automatically. The output is a lightweight, deployable classifier ready for production.
This speed and simplicity mean that whenever we identify a classification task in the future, we can spin up a dedicated model in under a minute. The cost savings and performance improvements are immediate and significant.
Want to learn more about Always Further?
Come chat with a founder! Get in touch with us today to explore how we can help you secure your AI agents and infrastructure.